A Distributed Multimodal Robotic Framework for Emotion-Aware Reminiscence Dialogue in Dementia Care
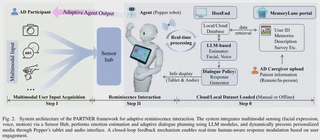
We introduce an embodied robotic implementation of the \textbf{PARTNER} framework (Personalized AI and Robotics to Nurture Engaging Reminiscence), a distributed multimodal architecture for emotion-aware, personalized dialogue in socially assistive contexts. The framework has three components: a secure cloud portal for managing media, a local server for processing multimodal inputs, and an embodied robot client. PARTNER combines auditory, visual, and textual inputs using Whisper for speech transcription and a vision–language model (GPT-4o) that infers implicit affect from facial snapshots and dialogue history, rather than relying on rigid emotion classifiers. To enhance reproducibility and support future model training, PARTNER incorporates a real-time logging pipeline that synchronizes user inputs, sensor streams, and model outputs into a structured dataset. We provide a system-level evaluation on our robot, measuring end-to-end command–response latency, transcription accuracy, and dialogue coherence under varied sensing and environmental conditions. Our experiments show sub-3,s loop latency on our testbed, robust transcription across various noise environments, and consistent responses during multi-turn dialogues, These findings validate PARTNER as a deployable platform for adaptive human–robot interaction. To our knowledge, PARTNER is the first Socially Assistive Robotics (SAR)-oriented system that (i) unifies a cloud portal for reminiscence media with a locally executed interaction server and an embodied agent, (ii) leverages VLM-based implicit affect cues for dialogue policy, and (iii) offers a real-time multimodal logging substrate to facilitate future domain-specific VLM/LLM fine-tuning.